TL;DR:
随着AI Agent的普及和多模态模型的爆发,传统数据架构已无法满足实时、复杂的数据需求。以Lance格式为核心的多模态数据湖,正成为支撑AI Agent智能涌现和企业级AI落地的关键基础设施,它通过优化数据存储、计算与管理,从根本上提升了AI系统的效率和上限。
当Seedream4.0和Sora2等前沿模型不断拓宽AI能力的边界,企业级AI的落地进程随之加速,智能体(AI Agent)的普及更是引发了底层数据架构的深层变革。过去以T+1分析结果为主导的传统湖仓一体架构,面对AI Agent实时交互、多模态数据消费的旺盛需求,其固有的延迟与单一数据类型处理能力已捉襟见肘。企业数据平台正经历一次从“静态分析仓库”到“实时数据服务层”的根本性转变,而这一转变的核心,正是多模态数据湖的崛起。
技术原理与架构重构:从“为人用”到“为模型服务”的范式跃迁
IDC预测,从2024年到2029年,多模态数据规模将以年均复合增长率接近30%的速度,在6年内增长3倍以上1。这一惊人的增速,早已超越了Databricks在2020年前后推动的“湖仓一体”架构(如Delta、Hudi、Iceberg等)所预期的结构化与半结构化数据处理范畴。AI的爆发不仅仅是模型层面的飞跃,它更深刻地重构了数据治理的对象和方式。合同PDF、客服录音、产品图片等曾被视为“难以利用”的非结构化资产,如今正被AI Agent转化为可检索、可问答的“数据金矿”,直接参与模型的检索增强与训练微调。
然而,这种从“为人理解和使用数据”到“让模型使用、消费和理解数据”的范式迁移,并非坦途。AI与多模态数据集的迭代周期面临巨大挑战:
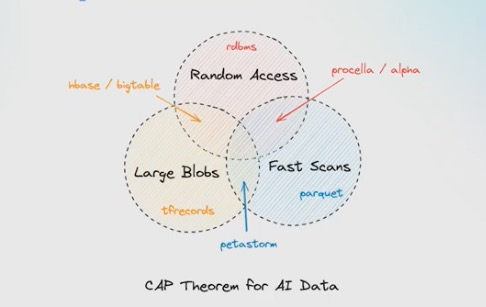
- 性能瓶颈:需同时满足快速扫描(过滤、EDA)、随机访问(搜索、训练shuffle)和大规模文件(图像、视频)高效流式传输到GPU的需求,传统系统难以兼顾。
- 成本与复杂性:为不同任务维护同一份数据的多份拷贝,在PB级数据规模下成本高昂,且需要耗费宝贵工程师资源进行手工转换和同步。
正是在这一背景下,AI产业迫切需要一种**“AI原生”的企业级数据架构**。火山引擎作为国内先行者,给出的答案是构建多模态数据湖,其核心在于:
- 统一底座纳管:在统一存储底座上,无缝纳管文本、图像、音视频乃至向量数据。这使得数据从“可存可查”升级为“即取即用”,支持上下文的动态组装,并实时服务于训练、检索与在线推理。
- Lance格式的战略选型:在调研多个开源技术路线后,火山引擎选择了Lance作为新的湖格式23。与传统的Parquet、ORC以及基于它们构建的Iceberg、Delta、Hudi不同,Lance从一开始就面向AI时代设计,目标是成为多模态数据的“单一事实来源”(Single Source of Truth),让不同模态数据能在同一张表中完成分析、检索与训练。其创新的文件格式兼具数据格式(Data Format)和表格式(Table Format)的双重特性,特别是“零成本数据演进”(Zero-cost Data Evolution)功能,允许动态增减数据列而无需复制历史数据包,显著解决了传统方案中的数据迁移难题4。
- 计算层的进化:面对大模型场景下远超传统搜索和报表的计算规模,火山引擎在现有Spark基础上持续优化,并敏锐捕捉到Ray的潜力,将其作为多模态分布式计算的基石,以应对图像、音视频等数据高效、分布式的处理需求2。结合Ray on Kubernetes技术栈,保障了算力的弹性调度和交付能力,适应AI工作负载潮汐般的算力需求。
王彦辉(火山引擎数智平台产品总监)指出:“最好的竞争力,一定来自生态。” 这强调了开放性与集成能力在新一代数据基础设施中的核心地位。
产业生态与商业价值:赋能企业级AI的效率飞轮
多模态数据湖的兴起,不仅仅是技术栈的更新,更是对企业AI生产力的一次深度赋能。从商业敏锐度看,其市场价值体现在多个维度:
- 降本增效:通过单一数据源避免多份拷贝的高昂存储成本。例如,在自动驾驶场景中,通过透明压缩机制使点云数据压缩率达到70%,显著缓解了网络带宽压力,并能通过列级读取优化GPU利用率从不足60%提升至90%以上1。
- 加速AI模型迭代:提供“为模型服务”的开放式底座,缩短从原始数据到可训练样本的路径。火山引擎沉淀的AI数据处理算子(如去重、质量评估、特征生成),让不具备强数据开发能力的团队也能低门槛处理多模态数据,将工程师从底层数据搬运中解放出来,专注于模型创新和AI应用开发2。
- 统一元数据管理:将管理对象从传统“表”扩展到模型、AI工具和Agent。同一份数据从获取、清洗到被哪些模型/Agent使用,效果如何,都能被追踪与评估,一旦线上指标抖动,可快速溯源,形成高效的AI数据闭环5。这构建了一个更为健壮和可控的AI开发环境。
- 开放生态与避免锁定:火山引擎秉持“集成而非替换”的原则,确保其多模态数据湖能与现有数据湖、计算引擎和AI平台顺畅对接,支持Ray、Daft、Spark等主流开源组件,这为企业提供了技术栈可选、架构可演进、无供应商锁定的灵活性,降低了企业采纳新技术的门槛和风险。
在投资逻辑上,多模态数据湖瞄准的是AI基础设施的“新基建”市场。随着AI Agent和多模态模型成为企业数字化转型的核心驱动力,对高效、弹性、AI原生数据底座的需求将呈爆炸式增长。火山引擎这样的服务商,通过提供一体化、高性能的解决方案,正在抢占这一战略高地,帮助企业将AI投入转化为实际的业务价值。
社会影响与未来展望:AI Agent智能涌现的深度与广度
AI Agent的上限,不再仅仅取决于其模型本身的参数量或算法的精妙,更深层地由其赖以学习和交互的底层数据湖决定。一个能够实时、高效、统一地处理和管理海量多模态数据的数据湖,将直接提升AI Agent的感知能力、情境理解能力和自主决策能力,从而实现更高水平的“智能涌现”。
以自动驾驶为例,这正是多模态数据湖最早落地的关键场景之一。摄像头图像、激光雷达点云、车载麦克风音频等多模态数据以前所未有的速度涌现,对实时处理和高效检索提出了严苛要求。火山引擎多模态数据湖的引入,帮助国内知名汽车企业在EB级数据场景下,实现了3倍处理效率提升和40%的模型训练交付速度加快,推动了智驾系统的快速迭代1。
展望未来3-5年,多模态数据湖将成为AI Agent基础设施的标配,并深刻影响人类文明进程的多个层面:
- 具身智能的加速发展:在机器人和具身智能领域,多模态数据湖将统一管理感知数据(视觉、听觉、触觉)和行为数据,支撑机器人更精准地理解物理世界和执行复杂任务,加速通用型机器人的研发与应用。
- 辅助决策与科学发现:在医疗影像领域,它能统一管理CT、MRI影像与病历文本,助力辅助诊断与新药研发;在工业制造中,处理传感器、视频监控和日志数据,实现预测性维护与质量检测,提升生产效率和安全性。
- 内容创作的革命:在AIGC(AI Generated Content)领域,多模态数据湖将组织海量的图像、视频与音频素材,为生成式AI提供高质量的训练数据底座,催生更富有创意和沉浸感的内容形式。
- 工作方式与社会结构变革:AI Agent因更丰富的数据感知能力,将渗透到更多专业领域,成为人类工作的智能副驾驶,从根本上改变人机协作模式,推动社会生产力的跃升。
然而,伴随多模态数据湖的普及,也必须正视其潜在的挑战。数据的偏见、隐私和安全问题在多模态、大规模场景下将更加复杂和隐蔽,需要更强大的数据治理框架、伦理准则和法律法规来保障。如何确保数据来源的合法性、使用的透明性以及结果的公平性,将是技术发展过程中不可避免的哲学思辨与社会责任。
归根结底,AI Agent的智能上限并非无边无际,它受限于我们为之提供的数据质量、广度、深度和处理效率。多模态数据湖的演进,正是我们为AI Agent插上翅膀,使其能更全面、更深入地感知和理解世界,从而开启一个真正由AI驱动的智能新纪元。
引用
-
为何底层数据湖决定了 AI Agent 的上限? · infoQ (2024/10/16) · 检索日期2024/10/26 ↩︎ ↩︎ ↩︎
-
多模态数据湖焕新升级,企业新一代AI Native的数据基建 - 知乎专栏 · 知乎专栏 · 火山引擎数智平台VeDI (2024/09/26) · 检索日期2024/10/26 ↩︎ ↩︎ ↩︎
-
LanceDB:AI时代的多模态数据湖- 文章- 开发者社区- 火山引擎 · 开发者社区 · 火山引擎 (2024/07/25) · 检索日期2024/10/26 ↩︎
-
LAS 平台Vibe Data Processing:AI 驱动的数据处理新范式 - 知乎专栏 · 知乎专栏 · 火山引擎数智平台VeDI (2024/09/29) · 检索日期2024/10/26 ↩︎
-
AI 数据湖服务LAS - 火山引擎 · 火山引擎 (2024/09/25) · 检索日期2024/10/26 ↩︎
{kind=link}