TL;DR:
中国信通院联合产业伙伴推出的“智域”大模型,基于Qwen3-32B,通过精细化的运维领域数据构建和多阶段模型训练,旨在提升企业SRE的故障诊断、预防和修复能力。这一开源举措不仅标志着垂直领域大模型在企业级AI应用的深化,更预示着运维从被动响应转向主动预测和智能决策,重塑产业生态与未来工作范式。
数字化转型浪潮与AI技术的深度渗透,正驱动各行各业寻求更高效、更智能的运营模式。在其中,保障复杂IT系统稳定运行的运维(Operations)工作面临前所未有的挑战:故障诊断的复杂性、预警的滞后性以及人工经验的局限性。在此背景下,大模型技术被寄予厚望,有望成为智能运维(AIOps)体系的核心基石。中国信息通信研究院(CAICT)与蚂蚁、腾讯、华为云等行业巨头联合推出的SRE领域大模型“智域”,正是这一趋势下的一个重要里程碑,它不仅是技术层面的创新,更深远地影响着企业级AI的落地路径、产业生态的演进以及未来人机协作的边界。
技术原理与创新点解析
“智域”大模型的核心创新在于其深度结合领域知识的精细化数据策略和多阶段迭代训练范式,旨在为系统“治未病、愈顽疾”1。
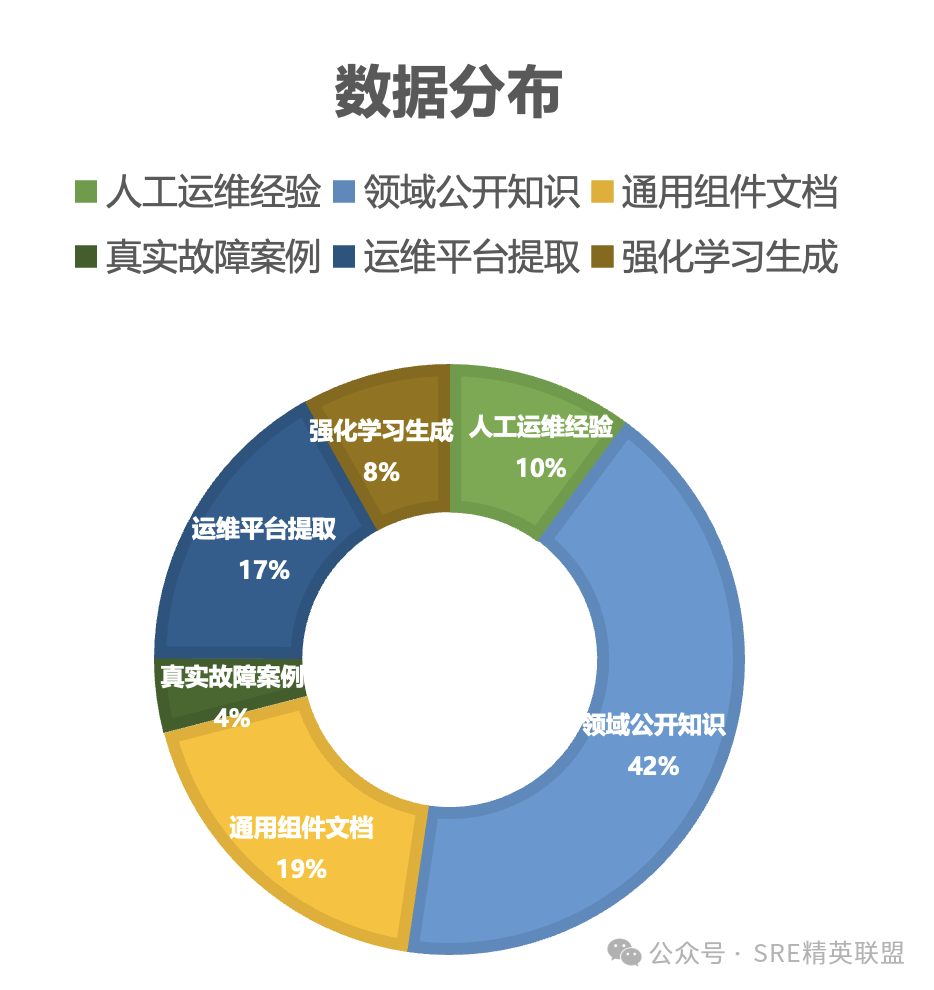
首先,在数据构建方面,“智域”摆脱了通用大模型对海量互联网数据的依赖,转而聚焦SRE领域的专业数据。其数据采集覆盖了六大类:领域公开知识(如《SRE实践白皮书》)、人工运维经验、通用组件文档(尤其强调国产化组件)、真实故障案例、运维平台提取的操作类数据,以及通过强化学习生成的专项能力数据1。这种多源异构、结构化与非结构化并存的数据集,确保了模型能够全面学习运维领域的“显性知识”和“隐性经验”。尤为值得关注的是,“智域”对人工运维经验和真实故障案例采取了人工编写和高权重增强,对领域知识和组件文档则辅助以大模型生成,最终形成约60亿词元(token)的SRE领域语料和35万条高质量运维问答对。1 这种**“人工精炼+模型辅助”的数据生成范式**,有效克服了传统数据集的稀疏性和偏见,为模型注入了高价值的领域专业性。此外,严格的数据清洗(格式规范化、质量评级、内容过滤、去重等)和数据增强策略,进一步保障了训练数据的精准性和可靠性,避免了“垃圾进,垃圾出”的问题。
其次,在模型训练上,“智域”以通义千问Qwen3-32B模型为基础2,采用了“增量预训练—微调—强化学习后再训练”的T字型策略。
- 增量预训练阶段,模型在SRE领域语料上进行知识前置注入,强化对批量运维通用知识的吸收。
- 监督微调阶段,针对高质量运维问答对进行定向优化,提升模型在故障诊断、根因分析、处置动作、运维SQL生成等具体任务上的专业技能。特别地,“智域”引入了Search-R1的“多轮迭代检索”框架,通过PPO算法训练模型实现自主决策和动态优化检索行为,显著提升了其上下文推理能力和抑制幻觉的拒答能力。这对于SRE这种对信息确定性要求极高的场景至关重要。
- 强化学习后再训练(RLHF/DPO)则是其独特的创新点,旨在解决领域模型训练中常见的“通用能力衰减”问题。通过对关键通用能力的评估和二次增强,确保“智域”在获得领域专长的同时,不失作为大模型的泛化和理解能力。这种平衡专业性与通用性的训练策略,是垂直大模型迈向成熟的关键。
“智域”模型已在“魔搭”社区公开,并支持NVIDIA VLLM和昇腾VLLM部署方式13,这大大降低了企业采纳和试用的门槛,有望加速其在产业中的应用落地。
产业生态与商业价值重塑
“智域”的发布,不仅是一项技术成果,更是对当前运维产业生态的一次深度洞察和重塑尝试。
当前,企业数字化转型深入,IT系统日趋复杂,故障排查和稳定性保障成为核心痛点。传统的AIOps虽有一定进展,但多基于规则和统计模型,难以应对多变、偶发和深层的“顽疾”。大模型的引入,使得运维从**“规则驱动”转向“知识与推理驱动”,从“事后处理”转向“事前预警与智能决策”**。
“智域”的商业价值体现在:
- 提升运维效率与系统稳定性:通过自动化故障诊断、根因分析和处置建议,显著缩短平均恢复时间(MTTR),降低人为失误,提升系统整体可用性。这直接转化为企业的运营效率提升和潜在的业务连续性保障。
- 固化专家经验,降低人才依赖:将SRE专家的宝贵经验沉淀为可复用的模型能力,打破了知识在少数个体间的壁垒,降低了企业对“明星SRE”的过度依赖,尤其在全球SRE人才稀缺的背景下,意义重大。
- 加速国产化适配与生态构建:“智域”对国产化组件的重点强化,响应了国家对信息技术自主可控的战略需求。其联合研发和开源部署模式,也有望吸引更多开发者和企业参与共建,形成良性循环的垂直领域大模型生态。
- 催生新商业模式与服务:基于“智域”模型,企业可以开发定制化的智能运维解决方案,提供SaaS化服务,甚至在保障自身业务的同时,将经验和能力输出给行业上下游伙伴。这为技术服务商和系统集成商带来了新的增长点。
这种由国家级研究机构牵头,联合头部科技公司共同研发并选择开源的模式,体现了中国在AI领域**“产学研用”深度融合的战略布局**。它旨在构建一个开放、共享的知识和技术平台,通过群策群力加速技术成熟和应用普及,而非仅限于单一厂商的商业闭环。这与阿里云通义千问Qwen3系列模型走向开源的趋势不谋而合,显示出开源正成为中国大模型公司在国际竞争中破局的“最优解”之一4。
运维范式演进与未来展望
“智域”大模型的推出,不仅是工具的革新,更是运维范式的深层演进。它将推动SRE从传统的“人肉运维”和“脚本运维”迈向**“智能体运维”**,即由具备自主推理和决策能力的AI Agent深度参与甚至主导部分运维流程。
在未来3-5年,我们可以预见:
- SRE角色的重塑:SRE工程师将从繁琐的日常故障排查中解放出来,更多地聚焦于系统架构优化、复杂问题建模、智能运维策略设计和人机协作流程的优化。他们的核心价值将从“解决问题”转向“构建可自愈、可进化的系统”。
- “治未病”能力的普及:大模型将通过对海量日志、指标、追踪数据的实时分析,实现更精准的异常检测和故障预测。结合强化学习,模型甚至能自主进行“预演”和“推演”,提前发现潜在风险并给出预防性建议,真正实现系统级的“治未病”。
- 多模态运维的兴起:未来的运维大模型将不仅限于文本,还会融合时序数据、拓扑图谱、甚至语音图像等多种模态数据,提供更全面的系统感知和更直观的故障可视化能力。
- 安全与伦理的挑战:随着AI在关键基础设施中的深度介入,其“幻觉”现象、数据偏见以及决策透明度将成为必须审慎对待的问题。如何建立有效的人工干预机制(Human-in-the-loop)、保证模型输出的可解释性、以及应对潜在的“黑箱”风险,将是技术发展中不可回避的伦理挑战。
- “数据飞轮”的持续加速:随着“智域”在实际生产环境中的应用,将有更多真实运维数据和故障案例被收集、清洗并反馈到模型训练中,形成一个正向的“数据飞轮”效应,驱动模型能力持续迭代提升,使其越来越“聪明”,越来越“可靠”。
从哲学层面看,“智域”的出现代表了人类对复杂系统管理能力的延伸和超越。它不仅仅是一个工具,更像是一个“智能副驾”,在数字世界的茫茫数据海洋中,帮助我们看清混沌、预判风险、甚至驾驭复杂性。然而,最终的决策权和责任仍然归属于人类,人与AI的协同智能,将是保障未来数字文明稳定运行的关键。
引用
-
面向运维的大模型!中国信通院“智域”大模型开放下载,为系统“治未病、愈顽疾”!·InfoQ(2024/07/25)·检索日期2024/07/25 ↩︎ ↩︎ ↩︎ ↩︎
-
通义大模型,Qwen3升级发布·阿里云(未知发布日期)·检索日期2024/07/25 ↩︎
-
智启通义千问3 模力全开·阿里云(未知发布日期)·检索日期2024/07/25 ↩︎
-
Qwen 3 发布,开源正成为中国大模型公司破局的「最优解」·智源社区(2025/04/30)·检索日期2024/07/25 ↩︎
{kind=link}